
티스토리 뷰
아래 누르시면 잡소리를 보실 수 있습니다.!
지난 포스팅에서 employees 예제 테이블 을 저장하는 작업까지 하여, 실습할 준비를 마쳤습니다.
사실 첫번째 어떤 포스팅을 할까 고민을 많이 했는데 SELECT * FROM 부터 시작하면 너무나 이야기도 길어지고,
공부보다 포스팅 하는데 시간을 많이 쏟을 듯 하여서 중요한 내용들부터 포스팅하며, 익숙해지도록 하겠습니다.
INDEX 의 가장 기초적인 내용을 다뤄보도록 하겠습니다.
INDEX 란?
INDEX(인덱스) 는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도 를 높여주는 자료구조이다.
간단한 예를 들어보겠습니다.
한권의 책이 있습니다. 이 책이 10장 내외에 책이라면 원하는 책의 내용을 찾을 때 빠르게 찾을 수 있겠죠 ?
하지만 이런 책이 10000장 이상으로 무수히 많은 내용들이 있다면, 우리는 책의 내용을 최악의 경우 10000번(무수히 많이)까지 찾아봐야 합니다.
그렇다면 원하는 내용을 찾기 위해서 어떤 부분을 확인해야 할까요?
바로 책의 목차 (차례) 를 찾아보게 될 것입니다.
INDEX 는 이러한 목차(차례)를 만드는 행위 라고 생각하시면 됩니다.
INDEX(인덱스)를 사용하는 이유는 ?
추가적으로 이러한 이유들이 있지만 지금은 아주 기초적인 부분만 설명을 하기위해 넘어가도록 하겠다.
읽어보도록 하자.
- WHERE 구문과 일치하는 열을 빨리 찾기 위해서.
- 열을 고려 대상에서 빨리 없애 버리기 위해서.
- 조인 (join)을 실행할 때 다른 테이블에서 열을 추출하기 위해서.
- 특정하게 인덱스된 컬럼을 위한 MIN() 또는 MAX() 값을 찾기 위해서.
- 사용할 수 있는 키의 최 좌측 접두사 (leftmost prefix)를 가지고 정렬 및 그룹화를 하기 위해서.
- 데이터 열을 참조하지 않는 상태로 값을 추출하기 위해서 쿼리를 최적화 하는 경우에.
*참고 : https://ra2kstar.tistory.com/96
실습
Workbench 를 통해 INDEX를 사용하는 이유를 보도록 하겠습니다.
Workbench 를 켜주시고, 새로운 SCHEMA(스키마)에 연습을 해보도록 하죠.
SCHEMAS 우클릭 해주시고 Create Schema... 를 클릭해줍니다.

다음과 같은 화면에서 이름은 간단하게 indextestdb 라고 하고, Apply 를 눌러줍니다.

우리는 Workbench 를 통해 시각적으로 편하게 생성을 하였지만, 다음과 같은 명령어를 통해 데이터베이스를 생성한다.
이 명령어에 익숙해지셔야 하며, 사실 Workbench 를 사용하는 것보다 명령 프롬프트를 사용하는 것에 익숙해지는 것이 좋다.(개인적으로 명렁어 작업이 더 빨리 할 수 있씀)
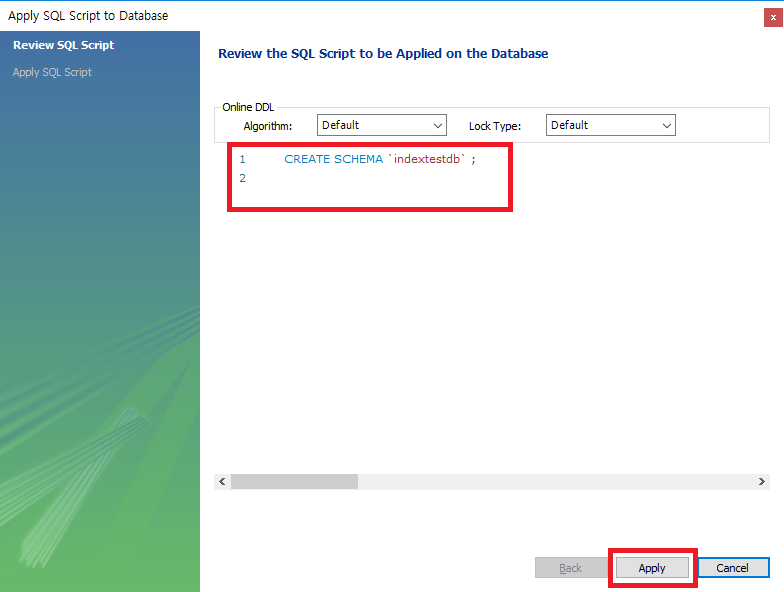
생성을 하고 나면 다음과 같이 데이터베이스가 생성됬음을 확인할 수 있다.
indextestdb 를 더블클릭 한다. ( indextestdb 에 접속한다 )

많은 데이터를 입력하기는 힘드니까,
employees 예제 레코드를 몇가지 복사할 수 있는 테이블을 생성해서 사용하도록 하겠습니다.
| CREATE TABLE indexTBL (first_name VARCHAR(14), last_name VARCHAR(16), hire_date DATE); |

employee의 레코드를 500개만 가져와서 테스트 해보도록 하겠다.
| INSERT INTO indexTBL SELECT first_name, last_name, hire_date FROM employees.employees LIMIT 500; |
[employees 데이터베이스 안의 employees 테이블의 컬럼 500개를 indexTBL 에 저장하겠다.]
그냥 실행을 누르면 모든 줄에 대한 결과를 반영하기 때문에 항상 블록을 잡고 실행하자!

자 그럼 여기서 간단한 조회를 해보도록 하겠습니다.
| SELECT * FROM indextbl WHERE first_name = 'Mary'; |
Mary 라는 이름을 찾을 겁니다.

그리고 나서 Workbench 의 조금 아래로 내리시면 Execution Plan 이 있는데 한번 눌러보죠!
없으시면 화살표 누르시면 나타납니다.!
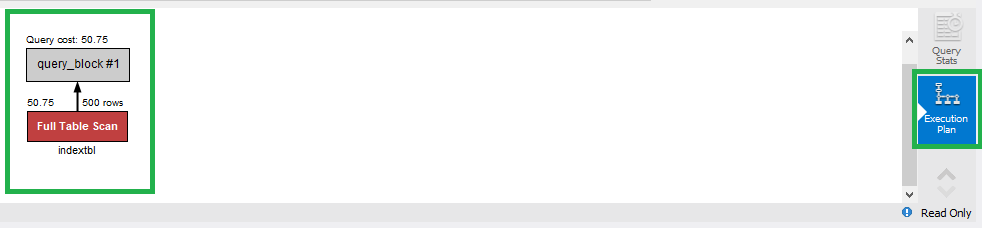
이 그림이 의미하는 것이 중요합니다.
비록 500개의 데이터를 조회했지만, Full Table Scan 이라고 되어있죠?
즉, 모든 Table 의 내용을 조회했다는 의미입니다.
이것이 만약 몇만개~몇억개의 데이터였다면, 검색 시간은 상당하겠죠?
드디어 인덱스라는 녀석을 사용해보도록 하죠.
| CREATE INDEX idx_indexTBL_firstname ON indexTBL(first_name); |
idx_indexTBL_firstname 은 임의의 인덱스 생성을 위한 이름 설정입니다.

그리고 나서 다시한번 Mary를 찾아보죠.
| SELECT * FROM indextbl WHERE first_name = 'Mary'; |
4번째줄 블록잡고 실행하셔도 됩니다.

다시 Workbench 의 살짝 아래쪽 Execution Plan 을 살펴보죠.

보시면 500 row -> 1row 그리고 50.75 -> 0.35 로 내용이 바뀐것이 눈에 보이시나요 ?
500개를 찾던 녀석이 바로 찾아내고! 시간도 빨라졌네요!
추가적으로 Non-Unique Key Lookup 이라는 것도 보이죠 ?! (이것에 대한 내용은 추후..)
이처럼 목차를 확인해서 빠르게 검색을 찾기 위한 조건을 실행하는 것이 INDEX 라는 녀석입니다.
정말 간단하게 실습을 통해 눈으로 확인해봤는데요.
사실 이 안에는 더 많은 내용이 숨겨져 있습니다.
예를 들면 INDEX 를 만들기 위해 TABLE 을 생성했고, INDEX 때문에 테이블 생성 속도 또한 느려진 셈이죠.
하지만 이러한 핸디캡? 에도 강점인 검색 속도 때문에 INDEX를 사용하는 것인데요.
왜 속도를 중요시 할까요?
우리가 인터넷 검색을 할때도 조금만 렉걸려도 상당히 답답하죠 ?
구글 검색을 하기위해 어떠한 단어를 쳤는데 이 검색이 1시간이 걸린다면 어떠실까요 ?
사용안하겠쬬?
(하지만 갓구글은 넘나 빠르다..)
이런 이유 때문에 INDEX는 상당히 중요한 부분입니다.
더 깊은 내용은 추후에 다루도록 하겠습니다!
그럼 이만!
(다음 포스팅 부터는 이런 세세한 부분은 빼야겠네요..ㅠㅠㅠ 어떻게 포스팅 할지 너무 고민 많이했지만..
이건 공부보다 일이 더 많네요 ...ㅋㅋㅋㅋㅋㅋ)
'데이터베이스 > MySQL' 카테고리의 다른 글
| 트리거(TRIGGER) 란 무엇인가? 실습을 통한 기초 이해하기 (0) | 2020.07.28 |
|---|---|
| 스토어드 프로시저(Stored Procedure)란 무엇인가? employees 예제를 통해 기초 알아보기 (3) | 2020.07.26 |
| 뷰(VIEW) 는 무엇인가? Employees 예제를 이용한 VIEW 이해하기 (0) | 2020.07.26 |
| MySQL 을 윈도우 명령프롬프트에서 접근 가능하도록 SETX PATH 잡기 (0) | 2020.07.25 |
| MySQL Server 및 Workbench 설치하기 (0) | 2020.07.25 |